Rails 4.2: Baixando os assets no slug do Heroku usando o Bower, pré-compilando e enviando diretamente para a Amazon S3 usando a gem Asset Sync.
A cada dia que passa eu estou mais encantado com o Heroku. Algumas vezes eu até me lamento pelo tempo que eu perdi aprendendo como configurar um servidor, mas logo em seguida eu caio na real e entendo que foi um passo importante para compreender uma série de coisas que vieram depois.
Um app Rails tradicional costuma ter quase nenhum problema para ser hospedado no Heroku. O processo chega a beirar um simples comando $ git push heroku master.
O caldo vai engrossando quando você precisa usar recursos mais sofisticados, mas mesmo assim, com um pouquinho mais de trabalho, sempre tem um jeito.
Eu pretendo mostrar neste post, quais são as modificações necessárias para você hospedar no Heroku um app Rails cujos assets são baixados usando o Bower. O fluxo de trabalho será mais ou menos o seguinte:
1. Você fará um push para o Heroku;
2. O slug iniciará no Heroku;
2. O Heroku instalará o Bower e baixará os assets;
3. O Heroku rodará o $ rake assets:precompile;
4. A gem Asset Sync enviará os assets do Heroku para um bucket na Amazon S3;
Coisa linda, hein?! Depois disso você nunca mais precisará rodar um
rake assets:precompilemanualmente.
Chega de teoria… vamos pra receitinha de bolo.
O que você não deve esperar deste post
Este post pressupõe que você já usa o Bower no seu app. Sendo asism, não vou citar detalhes sobre bower.json e outras coisas que você precisa fazer no seu app pra ele rodar.
Se precisar de informações básicas sobre o Bower, você pode assistir a minha palestra no TDC 2014:
http://www.infoq.com/br/presentations/rubygems-e-bower
Eu também não vou ficar aqui descrevendo tudo nos mínimos detalhes e com um monte de prints screen, ok? Imagino que você seja um programador e isso só faria você perder ainda mais tempo.
Configurando os buildpacks do projeto
Quando você manda um aplicativo para o Heroku, ele tenta detectar que tipo de linguagem o seu aplicativo necessita e usa uma receita de bolo pra instalar tudo que ele precisa. Essa receita chama-se buildpack.
Você pode conhecer todos os buildpacks default do Heroku no link abaixo:
https://devcenter.heroku.com/articles/buildpacks
Provavelmente seu aplicativo está usando o buildpack do Ruby. O problema é que este buildpack não possui o nodejs e nem o Bower. O que nós faremos é informar para o Heroku dois buildpacks: o do nodejs e o do Ruby.
Para isso, rode os comandos abaixo:
$ heroku buildpacks:add https://github.com/heroku/heroku-buildpack-nodejs
$ heroku buildpacks:add https://github.com/heroku/heroku-buildpack-rubyVocê pode conferir o resultado final usando o comando abaixo:
$ heroku buildpacks
=== my-project Buildpack URLs
1. https://github.com/heroku/heroku-buildpack-nodejs
2. https://github.com/heroku/heroku-buildpack-rubyNote que eu coloquei primeiro o buildpack do nodejs e depois o do Ruby. Eu fiz isso porque eu quero que o package.json seja executado primeiro para que o Bower baixe os assets antes do Rails efetuar a pré-compilação.
Ficou curioso sobre como o Heroku opera com múltiplos buildpacks? Dá uma olhadinha no link abaixo:
https://devcenter.heroku.com/articles/using-multiple-buildpacks-for-an-app
Instalando e executando o Bower no Heroku
Para instalar e executar o Bower no heroku, nós vamos usar um truque do npm. Nós criaremos um arquivo package.json e lá informaremos as dependências do nodejs e também o comando que deve ser rodado após estas dependências serem instaladas.
{
"private": true,
"name": "my-project",
"version": "0.0.0",
"license": "MIT",
"dependencies": {
"bower": "1.4.1"
},
"engines": {
"node": "0.12.5"
},
"scripts": {
"postinstall": "bower cache clean && bower install"
}
}Note que o script acima fará instalar o node 0.12.5, Bower 1.4.1, depois limpará o cache do Bower e assim baixará os seus assets usando o bower install.
Amazon IAM & Amazon S3
Nós precisaremos usar estes dois serviços da Amazon:
- Amazon S3: permite que você crie buckets de armazenamento de dados. É lá que nossos assets ficarão gravados.
- Amazon IAM: com ele nós criaremos uma identidade e uma senha que permitirá a nossa API fazer o upload de nossos assets na S3.
Criando um bucket na Amazon S3
A primeira coisa que você precisa fazer é criar um novo bucket na S3.
1. Entre no console do AWS
2. Acesse o serviço S3 – Scalable Storage in the Cloud
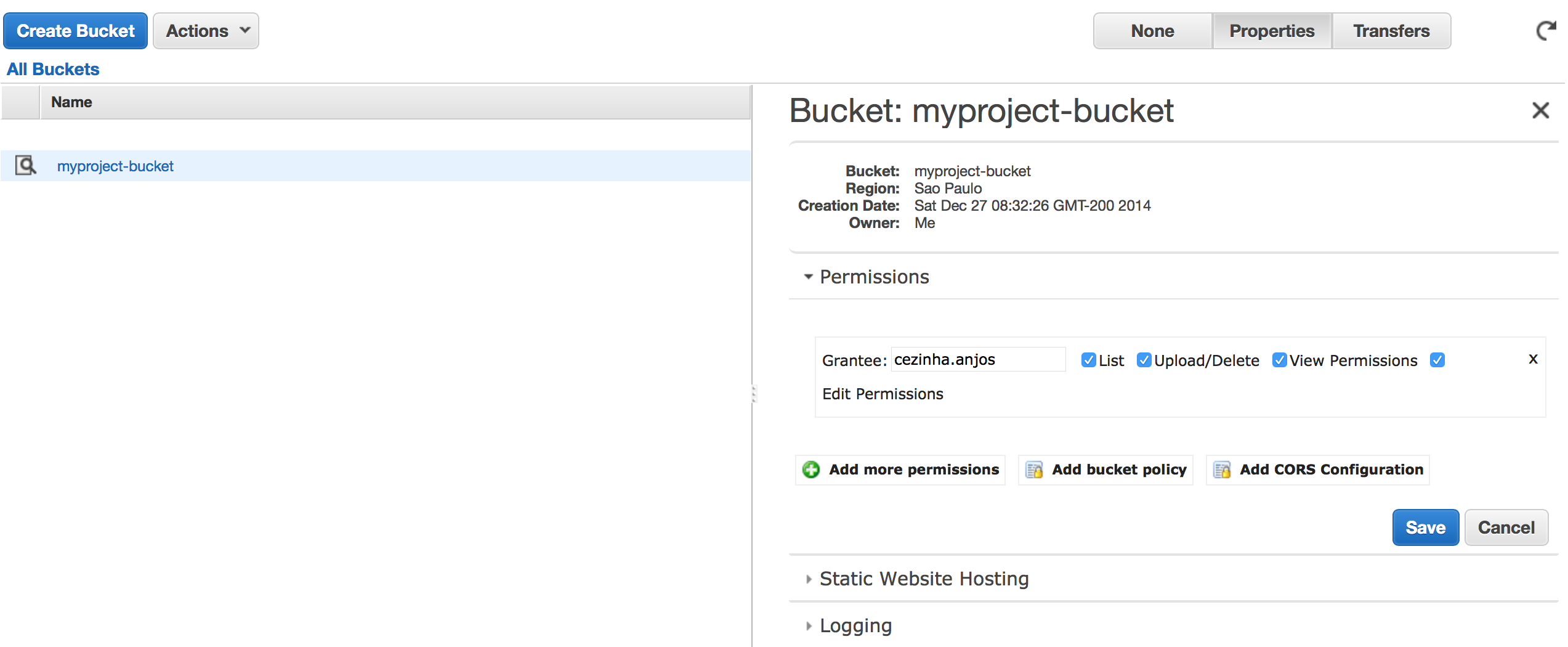
3. Crie um novo bucket para o seu projeto. Em nosso exemplo nós criaremos um chamado myproject-bucket. Importante: não use ponto no nome do bucket. Isso lhe dará dores de cabeça mais tarde.
4. Você agora precisa dar acesso público aos arquivos hospedados. Para isso clique em Add bucket policy e adicione a política abaixo:
{
"Version": "2008-10-17",
"Statement": [
{
"Sid": "AllowPublicRead",
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::myproject-bucket/*"
}
]
}Cada arquivo poderá ser acessado por qualquer um publicamente, desde que o solicitante saiba o nome do arquivo. Note que nós não demos acesso a listagem de arquivos.
5. Se você usa webfonts, então você precisa configurar também o CORS para o seu bucket. Se você não fizer isso, um erro de Cross-Origin Resource Sharing pode ocorrer. Para isso clique em Add CORS Configuration e cole o script abaixo:
<CORSConfiguration>
<CORSRule>
<AllowedOrigin>*</AllowedOrigin>
<AllowedMethod>GET</AllowedMethod>
<MaxAgeSeconds>3000</MaxAgeSeconds>
<AllowedHeader>Authorization</AllowedHeader>
</CORSRule>
</CORSConfiguration>6. Dê acesso total ao seu usuário. Em grantee selecione o seu usuário AWS e marque todas as opções. Veja a imagem acima.
Autorizando o acesso ao bucket via API com o IAM
1. Ainda no console do AWS acesse o serviço IAM – Identity & Access Manager.
2. Crie um novo access key. Não deixe de anotar o access key e um secret access key. Você precisará destes dois dados para que a gem Asset Sync possa ter acesso ao S3 via API.
3. Você agora precisa dar acesso a listar os buckets e a acessar o bucket do projeto. Para isso, anexe a seguinte Policy ao usuário criado:
{
"Statement": [
{
"Action": [
"s3:ListAllMyBuckets"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::*"
},
{
"Action": "s3:*",
"Effect": "Allow",
"Resource": "arn:aws:s3:::myproject-bucket"
},
{
"Action": "s3:*",
"Effect": "Allow",
"Resource": "arn:aws:s3:::myproject-bucket/*"
}
]
}Pronto! Os serviços da Amazon estão configurados. O próximo passo é mexer no seu aplicativo.
Modificações no seu projeto Rails
Por default o Rails gera os assets na pasta /assets. Em nosso exemplo nós faremos isso de forma ligeiramente diferente. Colocaremos em /production/assets. Assim, se for necessário um ambiente de staging, você pode manter os assets separados.
Vamos começar colocando tal pasta no .gitignore para não versioná-la indevidamente. Aliás, você usa git, né?!
# arquivo: .gitignore
/public/productionAdicione a gem Asset Sync no Gemfile. Aqui eu travei na versão 1.1.0, mas você pode consultar a versão mais atual no Rubygems.
Gemfile
gem "asset_sync", "1.1.0"Rode o bundler:
$ bundle installPara o ambiente de produção, você precisa ensinar ao Rails aonde os assets estão hospedados. Você faz isso mexendo no parâmetro asset_host.
Lembra que eu falei acima que estamos usando /production/assets ao invés de /assets? Isso é feito através do parâmetro prefix.
# arquivo: config/environments/production.rb
# Enable serving of images, stylesheets, and JavaScripts from an asset server.
# config.action_controller.asset_host = 'http://assets.example.com'
config.action_controller.asset_host = "//#{ENV['FOG_DIRECTORY']}.s3.amazonaws.com"
config.assets.prefix = "/production/assets"E deu! Só isso! Nenhuma outra mudança no projeto é necessária.
Variáveis de ambiente para o projeto
Os parâmetros de acesso a Amazon serão todos abastecidos via variáveis de ambiente. As configurações acima são as recomendadas pela gem, mas você pode tentar outras modalidades. Segue abaixo as variáveis necessárias:
AWS_ACCESS_KEY_ID=xxxxxxxxxxxx # preencha aqui os dados gerados pelo IAM.
AWS_SECRET_ACCESS_KEY=yyyyyyyy # preencha aqui os dados gerados pelo IAM.
FOG_DIRECTORY=myproject-bucket # nome do bucket do nosso projeto.
FOG_PROVIDER=AWS # aqui você está ensinando ao fog, a gem que de fato faz o upload, que ele fará isso na Amazon.
FOG_REGION=sa-east-1 # nosso bucket de exemplo está em hospedado em São Paulo.
ASSET_SYNC_GZIP_COMPRESSION=true # indica que a versão compactada das assets deve ser servida. Todas essas variáveis são importantes lá no Heroku. Senão ele não será capaz de acessar o bucket da S3 e enviar os assets.
Amarração final
Eu acredito que você encontre tudo o que precisa neste post para rodar o Bower no Heroku. Vale a pena ainda dar uma olhadinha em um outro post meu no qual eu explico como o Rails gera os figersprints nos arquivos gerados pela asset pipeline:
http://cezinha.info/2014/12/27/rails-4-2-upload-assets-na-amazon-s3/
Espero que este post tenha sido útil.
Links interessantes:
Gem AssetSync
Rails Guide – Asset pipeline in production
AkitaOnRails: Enciclopédia do Heroku